Víte, co udělá programátor, když si musí roztřídit fotky? Správně, napíše si na to program. A víte, co udělá informatik, když si musí roztřídit fotky? Navrhne si framework a spolu s ním i vlastní skriptovací jazyk. A napíše si na to program.
Co je to Disketo_Framework?
A teď vážně. Disketo_Framework, neboli zkráceně prostě disketo, je nástroj pro, řekněme pokročilé prohledávání diskových uložišť. Tedy všech pevných, nepevných, externích i interních disků, flash disků, pamětových karet a já-nevím-čeho-ještě. Zkrátka všeho, co obsahuje soubory a složky.
A proč? Nu, protože občas je nutné všechna tato uložiště projít a udělat si v nich pořádek. Ano, mluvím na vás, jež shraňují data roky, a pak jednou za čas, když jim začne docházet místo, tak vymýšlí co smažou. Ano, přesně na vás, jež jednou za dva roky zkopírují celý obsah svého počítače někam na externí disk a nazývají to záloha. Ano, na ty, co data ukládají raděj i vícekrát, a pak mají počítač přehlcený duplicitními daty.
Zkrátka asi na každého z nás, protože jen opravdu málo lidí se o svou IT techniku stará skutečně precizně. A takový člověk musí jednou za čas sednout, posbírat všechny externí disky, paměťové karty a flash disky a udělat si v nich pořádek. Vzít staré zálohy, a zálohy záloh, zálohy zálohy záloh, a buďto smazat, případně zaktualizovat. Vzhledem k tomu, že místa na disku je vždycky nedostatek, tak zálohy jsou stejně nekompletní a případně končí slovy: „no co, tak fotky jsem zálohoval loni a tak v nejhorším přijdu o fotky za letošek“.
Disketo neřeší žádný z uvedených problémů, to říkám rovnou. Ale může vám s nimi alespoň pomoct. Pomocí disketa si totiž můžete vyhledat
(a to je taky vlastně jediné, co disketo umí) různé soubory a složky podle různých kritérií.
A teď trochu techničtěji …
Aby člověk mohl disketo požívat musí se nejdříve ujasnit některé technické záležitosti. Disketo totiž původně tak trochu vzniklo pro programátory, protože některé věci si zkrátka naprogramovat musíte vy, i když chcete aplikaci jen používat. Ale v základu jej určitě může ovládat i trochu víc technicky zdatný uživatel.
Disketo je totiž kromě toho hodně orientován na linuxové operační systémy. To znamená jednak to, že se spouští z příkazové řádky, ale také to, že se nesnaží problémy vyřešit přímo, ale poskytnout data ve strojovém formátu, aby je mohly zpracovat další unixové nástroje jako např. less, grep, sed, find – nebo třeba i excel.
V neposlední řadě, pořád je disketo také programátorská platforma – chcete-li – knihovna, kterou je možné použít a dále její funkcionalitu rozvíjet. V takovém případě se očekává skutečně aktivní znalost Perlu. Ano, Perlu!
Základní myšlenka
Celé disketo totiž stojí na tom, že pro vyhledávání „problémových“ souborů či složek je třeba disketu říct, co hledáte. Na úvod třeba všechny složky, které obsahují fotky. Dále například všechny složky, které v názvu obsahují záloha a obsahují více než 90% shodných souborů. Nebo všechny páry složek, které mají alespoň jeden (dva, tři, …) společné wordovské dokumenty. A nebo prostě a jednoduše všechny složky, ze všemožných disků, flashek, cloudů a paměťovek, které obsahují něco, co se týká bakalářky.
Jak toho dosáhnout? Jednoduše a přitom složitě. Disketo toho umí relativně dost, ale je potřeba mu říct, co přesně je potřeba, aby našel. Na začátku (resp. na konci, ale k tomu se dostaneme) je vždycky seznam tzv. kořenových složek. Tedy složek, které chcete prohledávat. V praxi to většinou jsou přímo kořenové složky všech disků či uložišť (tj. na Windows C:\, D:\ a podob.). Samozřejmě, pokud hledáte třeba všechny fotky z léta 2016, asi nebudete nechávat disketo prohledat celý počítač, bohatě postačí jen Obrázky\fotky\.
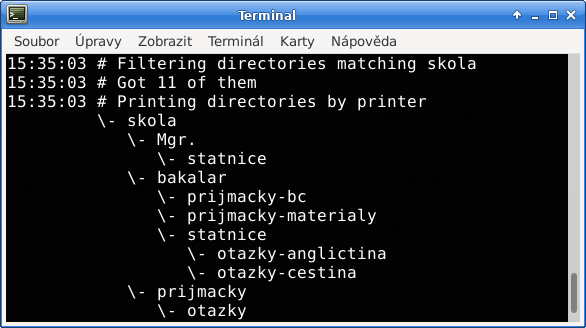
Dalším krokem, je potřeba ujasnit si, co vlastně hledám. Hledám složky podle názvu? Hledám složky s určitými soubory? Hledám duplicity? A nebo ještě něco jiného? Operace je samozřejmě možné kombinovat. A k tomu slouží tzv. disketo skripty.
Disketo skripty
Disketo skript pak není nic jiného, než seznam právě těchto operací, příkazů, úkolů. Tak například příkaz filter_directories_of_same_name ze seznamu všech složek vyškrtne ty, které jsou v něm jen jednou. Jinými slovy, nechá jen ty složky, které jsou v uložišti dvakrát. Samozřejmě, asi bude vhodné nejdřív vybrat jen složky, které nás zajímají, tedy: filter_directories_by_pattern.
Tento příkaz vyžaduje uvést, jaké složky se mají ponechat a jaké vyhodit – na základě názvu, pochopitelně. Tedy například "fotky", "škola" nebo "zaloha". Je také možné uvést $$, v takovém případě bude hodnota zadána až při spuštění. To se hodí pro opakovatelně použitelné disketo skripty s jinak stejnou konfigurací.
Na závěr je slušnost přeživší složky vypsat – tedy příkaz print_directories_simply. Výsledný skript by pak vypadal následovně (první a druhý příkaz byly prohozeny, je rozumné nejdříve vyřadit složky, které nepasují názvem, až pak ty, které se neopakují):
|
1 2 3 |
filter_directories_by_pattern $$ filter_directories_of_same_name print_directories_simply |
Takto připravený skript uložíme do souboru, třeba slozky.ds a můžeme spustit. Protože obsahuje jedenkrát $$, bude při spuštění vyžadovat zadání jedné hodnoty – vzoru pro filtrování složek.
Spouštění
Disketo se spouští pomocí tzv. interpretu disketo skriptů, tedy prográmku run-disketo-script.pl. Jeho použití je následující:
|
1 |
./run-disketo-script.pl <SKRIPT> <ARGUMENTY SKRIPTU...> <KOŘENOVÉ SLOŽKY...> |
Jeho prvním argumentem je název (cesta) souboru disketo skriptu. Následují argumenty skriptu a na konci je pak seznam (kořenových) složek, které má disketo prohledávat.
Vezměme si náš disketo skript slozky.ds. Budeme chtít prohledat složky skola a zaloha, a hledat v nich všechny duplicitní složky s názvem statnice. Spuštění se provede následujícím příkazem:
|
1 |
./run-disketo-script.pl slozky.ds "statnice" ~/skola/ ~/zaloha/ |
Výstup bude následující:
|
1 2 3 4 5 6 7 8 9 10 11 |
19:54:46 # Listing all directories in /home/martin/skola/, /home/martin/zaloha/ 19:54:46 # Got 13 of them 19:54:46 # Filtering directories matching statnice 19:54:46 # Got 7 of them 19:54:46 # Filtering directories of same name 19:54:46 # Got 3 of them 19:54:46 # Printing directories simply /home/martin/skola//Mgr./statnice /home/martin/skola//bakalar/statnice /home/martin/zaloha//skola/magistr/statnice 19:54:46 # Printed 3 of them |
Jak vidno, disketo nám vypsal spoustu informací. Pokud nás nezajímají informativní hlášky o průběhu (hodí se vědět, jak dlouho která operace probíhala, můžou to totiž být i hodiny), můžeme je skrýt přesměrováním standartního chybového výstupu do /dev/null:
|
1 2 3 4 |
$ ./run-disketo-script.pl slozky.ds "statnice" ~/skola/ ~/zaloha/ 2> /dev/null /home/martin/skola//Mgr./statnice /home/martin/skola//bakalar/statnice /home/martin/zaloha//skola/magistr/statnice |
Nyní už vidíme jen seznam tří složek, které mají v názvu (resp. v celé cestě) statnice a současně mají shodný název s některou z jiných (zde všechny tyto tři současně). Když zkusíme vyhledat prijmacky, dostaneme:
|
1 2 3 |
$ ./run-disketo-script.pl slozky.ds "prijmacky" ~/skola/ ~/zaloha/ 2> /dev/null /home/martin/skola//bakalar/prijmacky-materialy /home/martin/zaloha//skola/prijmacky-materialy |
Samozřejmě, disketo vyhledává slovo od slova. Při vyhledávání statnice nenajde ani státnice ani statnicove-otazky. Obecně, s češtinou (ve smyslu diakritiky) bude mít disketo zřejmě nemalý problém. Za to se omlouvám, řešení by bylo komplikované.
Další funkce
Například následující disketo skript vyhledá všechny složky, které mají zvolený název, a které obsahují alespoň jeden wordovský dokument:
|
1 2 3 |
filter_directories_by_pattern $$ filter_directories_by_files_pattern "docx" 1 print_directories_simply |
Abyste si nemuseli pamatovat, jaké hodnoty skript kde vyžaduje (obzvlášť, pokud bude skript vyžadovat parametrů více), příkaz ./run-disketo-script.pl dokumenty.ds (tedy zavolání disketa jen s názvem skriptu, bez dalších hodnot a složek) vám požadované argumenty vypíše:
|
1 2 |
Expected at least 2 arguments, given 0 Usage: ./run-disketo-script.pl dokumenty.ds <pattern of filter_directories_by_pattern> <DIRECTORY...> |
Co dělá který příkaz a co znamená každý z jeho argumentů by mělo být poměrně intuitivní, takže k nim není dodávána žádná další dokumentace. Zájemci mohou konzultovat zdrojový kód modulu Disketo_Extras, kde jsou implementovány.
Pro opětovné ozkoušení, jestli jste uvedli správné hodnoty lze použít přepínač --dry-run. Ten, klasicky, spustí disketo skript s reálnými hodnotami (ať už přímo ze skriptu nebo zadané při spuštění), ale nebude prohledávat disk (což ušetří čas). Tedy:
|
1 2 3 4 5 6 7 8 9 |
$ ./run-disketo-script.pl --dry-run dokumenty.ds otazky ~/skola/ ~/zaloha/ Will invoke list_all_directories: with directories /home/martin/skola/, /home/martin/zaloha/ Will invoke filter_directories_by_pattern: pattern := $$, which is currently otazky Will invoke filter_directories_by_files_pattern: pattern := docx threshold := 1 Will invoke print_directories_simply: |
Pokud jej necháme skutečně proběhnout (tj. bez --dry-run), vypíše nám něco následujícího:
|
1 2 3 4 5 6 7 8 9 10 11 |
./run-disketo-script.pl dokumenty.ds otazky ~/skola/ ~/zaloha/ 14:43:20 # Listing all directories in /home/martin/skola/, /home/martin/zaloha/ 14:43:20 # Got 23 of them 14:43:20 # Filtering directories matching otazky 14:43:20 # Got 7 of them 14:43:20 # Filtering directories matching files pattern docx w/ at least 1 14:43:20 # Got 2 of them 14:43:20 # Printing directories simply /home/martin/skola//prijmacky/otazky /home/martin/zaloha//skolni-veci/vypracovane-otazky/stanice 14:43:20 # Printed 2 of them |
Jak vidíte, skutečně nám vypsal všechny (složky i podsložky), které v názvu obsahují otazky (a přitom obsahují alespoň jeden dokument *.docx).
Pár poznámek
Do disketo skriptů lze vkládat komentáře. Nijak neobvykle, řádek začínající # je ignorován až do svého konce.
Přepínač --dry-run už jsem zmínil. Vypíše, jaké příkazy disketo provede a s jakými hodnotami. Seznam všech příkazů a jejich parametrů se vypíše pomocí příkazu./run-disketo-script.pl --list-functions . Bohužel, nechtělo se mi psát se s dokumentací, takže případné informace o to, co patřičný příkaz dělá, vás odkážu na modul Disketo_Extras.
Disketo ve většině případů pracuje pouze s názvem souborů či složek. Předpokládá totiž, že chceme-li hledat složky s excelovskými tabulkami, budeme hledat soubory s příponou xls nebo xlsx, při hledání fotek jpg a podob.
S tím souvisí – pokud je některý z parametrů nazván pattern, pak ve skutečnosti očekává regulérní výraz, navíc case sensitivní, tedy rozlišující velká a malá písmena. Takže např. pro vyhledání fotek (malými nebo velkými písmeny) je třeba použít [fF][oO][tT][kK][yY] popř. (fotky)|(FOTKY). Pro vyhledání „fotky nebo foto“ pak třeba fot(o|ky).
Pokud se regulérní výrazy neznáte, mělo by být možné použít namísto nich běžný text. Je tedy třeba akorát hlídat si malá a velká písmena a vyhnout se použití speciálních znaků (závorky, pomlčky) (nebo před každý z nich dát zpětné lomítko). Pokud chcete vzor, který splňuje každý text, použijte např. (.*) (to se hodí, pokud je pro vás některý z filtrů zbytečný, nebo jej chcete jen rychle deaktivovat).
Obdobně, parametry jako printer nebo matcher musí být perlovské subrutiny, tedy funkce. Díky tomu je možné doprogramovat prakticky libovolný způsob, jak porovnávat, vypisovat, či vyhledávat soubory a složky. Tak například následující skript:
|
1 2 3 4 5 6 7 8 9 10 11 |
# vypise jednoduchy adresarovy strom veci k mgr studiu filter_directories_by_pattern "magistr|mgr|Mgr." print_directories sub() { my $dir = shift @_; my @parts = split(/\/+/, $dir); my $name = pop @parts; my $count = scalar @parts; return ("| " x $count) . "+ $name"; } |
Vypíše:
|
1 2 3 4 5 6 |
| | | | + Mgr. | | | | | + statnice | | | | | + magistr | | | | | | + statnice | | | | | | | + otazky | | | | | + prijmacky-mgr |
Na závěr už snad jen – v instalaci disketa se nachází adresář scripts, který obsahuje pár základních skriptů. Asi nebudou úplně pro přímé použití, nicméně třeba poslouží jako inspirace.
Kde a jak?
Disketo najdete na mém GitHubu, není to samostatný repozitář, je součástí mého projektíku shell-utils.
Disketo – kromě perlu, pochopitelně, nemá žádné jiné závislosti nebo požadavky. Stačí mít jen v počítači perl a spustit ./run-disketo-script.pl, popř. perl run-disketo-script.pl.
V samostatném článku pak ukážu, jak si s pomocí disketa udělat pořádek ve fotkách.