Tento článek navazuje na předcházející článek, ve kterém jsem představil prográmek disketo. Ten slouží k vyhledávání souborů a složek na základě rozličných kritérií, jako je název složek či souborů v nich obsažených, počet souborů určitého typu, nebo počet shodných souborů ve dvou (a více) různých složkách.
V tomto článku se podíváme na trochu reálnější použití disketa – a to úklid ve fotkách. Fotek totiž často bývá hodně, bývají z různých zařízení – a často od různých lidí. Některé jsou poctivě roztříděné, některé méně, některé jen tak narychlo zkopírované. Občas je na čase sednout a projít si všechny místa, kde se fotky nacházejí (počítače, flashky, externí disky, paměťovky, cloudy, …) – a udělat v nich pořádek. Sesypat do jedné složky, smazat ty které už mezitím byly roztříděny a naopak případně roztřídit ty, které roztříděné nejsou.
Disketo může být v mnohém z toho poměrně nápomocné. Umožní vám najít celkem očividně zapomenuté či neroztříděné fotky – a to dokonce bez toho, aniž byste vůbec museli vidět jedninou fotku. Chcete to zkusit? Pojďme se do toho pustit.
Ještě než se do toho radostně pustíte, jen bych připomněl, že disketo asi není prográmek pro běžného uživatele. Pro jeho používání je vyžadována pokročilá znalost práce s počítačem na úrovni ovládání příkazové řádky a základů programování či skriptování.
Složky s fotkami (první způsob)
Základem každého třídění je sesbírat si všechny možné složky ze všech možných míst. Vezmeme disketo a vylistujeme se všechny složky, jež se jmenují např. foto či fotky. Jak už víme, disketo pracuje s regulérními výrazy, takže je možné názvy zkombinovat. Je tak možno použít např. vzor fot(o|ky). Pozor však na malá a velká písmena, ty disketo rozlišuje.
Předchozí vzory nám vylistují všechny složky, odpovídající (jejiž celá cesta odpovídá) zadanému vzoru. Tedy všechny složky foto a fotky a to včetně podsložek. Můžete se tak přesvědčit, jak strašně velké množství složek s fotkami doma máte. Nás ale na úvod bude zajímat jen ty samotné složky foto či fotky, bez jejich podsložek. Toho se naštěstí dá v disketu dosáhnout docela snadno, stačí říct, že cesta musí textem foto nebo fotky končit, tedy fot((o)|(ky))/?$ (volitelné lomítko na konci je jen pro jistotu).
Pak už stačí složky jen vypsat. Disketo skript slozky-s-fotkami-1.ds tedy bude vypadat následovně:
|
1 2 3 |
# Slozky s fotkami (prvni zpusob) filter_directories_by_pattern "fot((o)|(ky))/?$" print_directories_simply |
Skript spustíme se seznamem všech našich uložišť (v mém případě složky obrazky a zaloha přímo v počítači):
|
1 2 3 4 5 6 7 8 9 |
$ ./run-disketo-script.pl slozky-s-fotkami-1.ds ~/obrazky/ ~/zaloha/ 16:16:31 # Listing all directories in /home/martin/obrazky/, /home/martin/zaloha/ 16:16:32 # Got 21 of them 16:16:32 # Filtering directories matching fot((o)|(ky))/?$ 16:16:32 # Got 2 of them 16:16:32 # Printing directories simply /home/martin/obrazky//fotky /home/martin/zaloha//foto 16:16:32 # Printed 2 of them |
Složky s fotkami (druhý způsob)
Pokud však máte ve fotkách totální chaos a nemůžete ani říct, jak se vlastně jmenují všechny složky s fotkami, je tu druhá možnost. Můžete zkusit vyhledat složky obsahující fotky, tedy JPG soubory. Takových bude ovšem hromada (JPG soubory jsou jeden ze základních formátů obrázku, takže i bez fotek jich v počítači budete mít tisíce).
Prostý vzor (.*)\.jpg by tak našel zbytečně moc souborů. Lepší by bylo použít vzor například PICT_[0-9]{7}\.JPG, pokud váš foťák produkuje soubory ve formátu PICT_1234567.JPG. Samozřejmě, i zde se vzory dají kombinovat, takže můžete vytvořit vzor třeba (PCIT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg). Stejně jak v minulém případě je rozumné ukončit vzor znakem $ (lomítko už nyní opravdu nehrozí; pokud tedy nemáte na disku složku s názvem odpovídající vzoru).
Použijeme skript slozky-s-fotkami-2.ds, který prvně vyfiltruje podle názvu adresáře (podobně jako v předešlém případě, ale mírněj). To se může hodit např. pro vyloučení složky Windows, resp. omezení vyhledávání jen na uživatelské adresáře, ale není nic špatného nastavit tento parametr na (.*) (nebo rovnou celý řádek vypustit).
Dále provede filtraci podle souborů. A to tak, že sítem projdou všechny složky, které obsahují soubory dle vzoru výše, a to, pokud jich obsahuje alespoň uvedený počet. My tuto volbu ponecháme na uživateli. Čím nižší číslo, tím více falešně pozitivních složek disketo najde (např. grafika k programům), naopak čím vyšší, tím víc skutečných složek s fotkami bude ignorováno. Bude to chtít trochu experimentování, proto jej necháme uživateli zadat až při spuštění. Tedy:
|
1 2 3 4 |
# Slozky s fotkami (druhy zpusob) filter_directories_by_pattern "fo" filter_directories_by_files_pattern "(PICT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg)" $$ print_directories_simply |
A spustíme (budeme hledat složku s alespoň dvěma fotkami):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ ./run-disketo-script.pl slozky-s-fotkami-2.ds 2 ~/obrazky/ ~/zaloha/ 16:44:44 # Listing all directories in /home/martin/obrazky/, /home/martin/zaloha/ 16:44:44 # Got 22 of them 16:44:44 # Filtering directories matching fo 16:44:44 # Got 9 of them 16:44:44 # Filtering directories matching files pattern (PICT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg) w/ at least 1 16:44:44 # Got 5 of them 16:44:44 # Printing directories simply /home/martin/obrazky//fotky/Jarka /home/martin/obrazky//fotky/loni /home/martin/obrazky//fotky/mobil /home/martin/zaloha//foto/dovolena-2019 /home/martin/zaloha//skola/nafoceny-projekt 16:44:44 # Printed 5 of them |
Zajímavostí je, že nyní jsme našli i fotky školního projektu, které nám předchozí skript nenalezl.
Jen tak mimochodem, při velmi vysokém čísle (stovky či třeba tisíc) pak můžete obdržet složky, které obsahují enormní množství fotek. Získáte tak přehled – jednak o tom na jaké akci (či v jakém časovém úseku) jste opravdu hodně fotili – ale zřejmě také o tom, která složka pravděpodobně obsahuje nevytříděné a nepromazané fotky.
Hledání duplicit – složky
Výborně, máme tedy seznam všech složek obsahující fotky. Ze by bylo fajn si jej ručně projít a zkontrolovat. Přecijen, v počítači můžete mít různé složky a vzoru tak může odpovídat i například složka Xbfotoxb20am, která ale zřejmě nebude obsahovat fotky.
Také se ukázalo rozumným shromáždit si všechny složky s fotkami na jedno místo. Založte si složku třeba UKLID_FOTKY a všechny si tam nakopírujte/přesuňte. Zjednoduší to práci i vám i disketu, který nebude muset pořád dokola prohledávat všechna uložiště (bohužel, disketo je v tomhle poněkud hloupý a tak prohledává pokaždé vše, bez ohledu na to, jestli se něco změnilo či ne).
Máte? Výborně. (Já tento krok v rámci jednoduchosti vynechávám.) Nyní se jen tak pro kontrolu podíváme, jestli některou ze složek s fotkami nemáte dvakrát (či dokonce vícekrát). Přecijen – často člověk zálohuje až moc – a některé zcela totožné fotky může mít na více místech – i když jsou to pokaždé tytéž. Necháme disketo, ať vám vyhledá duplicitní složky (v první fázi pouze takové, které mají shodný název). Použijeme následující skript:
|
1 2 3 4 5 |
# Hledani duplicit (slozky) filter_directories_by_pattern "fo" filter_directories_by_files_pattern "(PICT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg)" $$ filter_directories_of_same_name print_directories_simply |
Disketo vám vypíše všechny složky, které mají nějaké „dvojče“ (tj. jinou složku se stejným názvem). Jak si vypsat, která (či které, pokud je jich víc) to je, si povíme za chvíli.
V mém případě však žádné duplicitní složky nenalezl, takže jdeme pátrat dál.
Hledání duplicit – soubory
Když dva dělají totéž není to totéž – a stejně tak, když se dvě složky jmenují stejně, neznamená to, že jsou si věrnou kopií. Složky s názvem „dovolená u moře“ „vánoce u Nováků“ či „šedesátiny“ by mohly vyprávět.
Pomocí disketa můžeme i tyto hříšníky odhalit. Použijeme skript pro vyhledání složek s duplicitními soubory. Skript porovná všechny složky (včetně jejich obsahů) mezi sebou navzájem a pokud najde shodu (složka obsahuje víc než zadaný počet shodných souborů), složku vypíše.
A podle čeho je bude porovnávat? Nejjednodušší je porovnávání podle názvů souborů. Takový disketo skript bude vypadat následovně:
|
1 2 3 4 5 |
# Hledani duplicit (soubory) filter_directories_by_pattern "fo" filter_directories_by_files_pattern "(PICT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg)" $$ filter_directories_with_common_file_names $$ print_directories_simply |
Pro případ, že by název souboru nebyl dostatečný (např. pokud foťák čísluje vždy od nuly a stejné názvy souborů by se tak často opakovaly) je možné porovnávat nejen podle názvu souborů, ale také podle velikosti. Minimálně u fotek je poměrně nepravděpodobné, že by dvě fotky měly stejný název i stejnou velikost. V takovém případě se namísto filter_directories_with_common_file_names použije filter_directories_with_common_file_names_with_size.
Teoreticky by také bylo možné porovnávat podle data poslední změny či vytvoření souboru. To však u souborů, které vznikly zkopírováním moc nedává smysl (soubor kopie vzniká až při kopírování, nemá tedy stejný čas vzniku jako původní soubor), takže v disketu není implementován a musel by se naprogramovat ručně (což ovšem není nemožné, disketo s tím tak trochu počítá).
Každopádně, my se budeme držet původního porovnávání dle jména souboru. Skript nám vypsal, které složky mají nějaké „dvojče“, ale nevíme jaké:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
19:13:59 # Listing all directories in /home/martin/obrazky/, /home/martin/zaloha/ 19:13:59 # Got 26 of them 19:13:59 # Filtering directories matching fo 19:13:59 # Got 12 of them 19:13:59 # Filtering directories matching files pattern (PICT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg) w/ at least 1 19:13:59 # Got 5 of them 19:13:59 # Filtering directories with at least 1 common file names 19:13:59 # Got 4 of them 19:13:59 # Printing directories simply /home/martin/obrazky//fotky/loni /home/martin/obrazky//fotky/mobil /home/martin/zaloha//foto/dovolena-2019 /home/martin/zaloha//skola/nafoceny-projekt 19:13:59 # Printed 4 of them |
Abychom to zjistili, budeme změnit způsob, kterým se vypisují nalezené složky, tj. poslední příkaz našeho skriptu. Bohužel, teď už se neobejdeme bez aktivního programování, je potřeba naprogramovat vlastní „vypisovač“, tedy subrutinu, která vypíše, co přesně potřebujeme. V našem případě chceme vypsat u každého nalezené složky také ty, které jsou jejími dvojčaty (opět, může jich být víc). Bez dalšího vysvětlování:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Hledani duplicit (soubory), lepsi vypis filter_directories_by_pattern "fo" filter_directories_by_files_pattern "(PICT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg)" $$ filter_directories_with_common_file_names $$ print_directories sub { my ($left) = @_; my ($filtered_ref, $intersects_ref) = @{ $previous_ref }; my $rights_ref = $intersects_ref->{$left}; my $rights_str = join(",\t", (keys %{ $rights_ref })); return "$left ->\t $rights_str"; } |
Výsledek je mnohem informativnější (pro lepší přehlednost doporučuji zkrátit cesty, tj nahradit např. /home/martin/obrazky za O a /home/martin/zaloha za Z):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
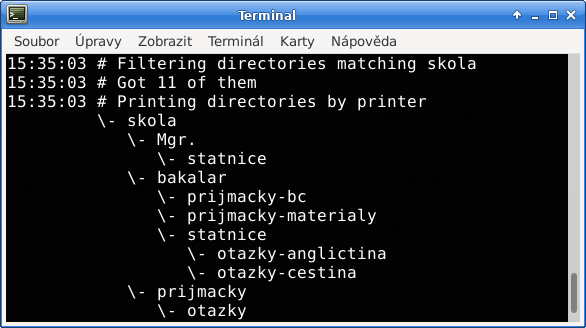
19:17:55 # Listing all directories in /home/martin/obrazky/, /home/martin/zaloha/ 19:17:55 # Got 26 of them 19:17:55 # Filtering directories matching fo 19:17:55 # Got 12 of them 19:17:55 # Filtering directories matching files pattern (PICT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg) w/ at least 1 19:17:55 # Got 5 of them 19:17:55 # Filtering directories with at least 1 common file names 19:17:55 # Got 4 of them 19:17:55 # Printing directories by printer /home/martin/obrazky//fotky/loni -> /home/martin/zaloha//skola/nafoceny-projekt /home/martin/obrazky//fotky/mobil -> /home/martin/zaloha//foto/dovolena-2019 /home/martin/zaloha//foto/dovolena-2019 -> /home/martin/obrazky//fotky/mobil /home/martin/zaloha//skola/nafoceny-projekt -> /home/martin/obrazky//fotky/loni 19:17:55 # Printed 4 of them |
Vidíme tedy, které složky obsahují podezřele společné soubory. Je tu jistá šance, že se jedná o kopii téhož obsahu – v našem případě složka nafoceny-projekt poměrně pochopitelně obsahuje také soubory ze složky s fotkami, proto se nám vypsala. Často ale jen narazíme na složku, která jen obsahuje neprotříděné či nepromazané soubory oproti jiné – a přitom se nám vypíše jako duplicita.
Tomu asi úplně nejde zabránit, nicméně mohli bychom si vypsat, kolik souborů obsahuje první složka, kolik druhá – a kolik z nich mají společné. (Šlo by vypsat soubory všechny, ale to by bylo poněkud nepřehledné.) Něco takového najdeme v souboru scripts/find-common-directories.ds. Ten nám vypíše (první číslo je počet souborů složky na začátku řádku, druhé číslo počet společných souborů a třetí číslo počet souborů v druhé složce):
|
1 2 3 4 |
/home/martin/obrazky//fotky/loni --> /home/martin/zaloha//skola/nafoceny-projekt: 3/2/2 /home/martin/obrazky//fotky/mobil --> /home/martin/zaloha//foto/dovolena-2019: 4/3/3 /home/martin/zaloha//foto/dovolena-2019 --> /home/martin/obrazky//fotky/mobil: 3/3/4 /home/martin/zaloha//skola/nafoceny-projekt --> /home/martin/obrazky//fotky/loni: 2/2/3 |
Pokud jsou všechna tři čísla stejná, pak jsou obsahy obou složek (zřejmě) totožné. Než ale jednu z nich smažete raději si je obě otevřete a obsahy zkontrolujte (jak jsem psal, porovnáváme pouze na základě názvů souborů).
Další poměrně pozitivní případ je typu 120/49/49 (a pochopitelně tedy i zrcadlový), tedy že všechny soubory z druhé složky se dají najít také v první složce. Soubory v druhé složce tak nejspíš oproti té první prošly promazáním či roztříděním. (A nebo se naopak část z nich ztratila při překopírování!)
Pokud budou čísla zcela rozdílná, pak se bude jednat o naprostý mišmaš a fotky bude bohužel potřeba projít ručně.
Hon na Otesánka
Máte-li odebrány všechny duplicitní fotky a stále máte pocit, že vám moc místa na disku neubylo? Můžete se zkusit poohlédnout po největších žroutech místa na disku. V případě fotek to budou pravděpodobně videa. Dost možná tam někde máte dvouminutový záběr vaší kamarádky, jak tančí v temném baru na stole. Ano, přesně ten typ videí, kde není absolutně nic vidět, zato je tam slyšet celá hospoda. Pominu-li fakt, že takováto videa by vůbec neměla vznikat, natož se dostat až do rodinného alba, tak mohou být taky poměrně pěkný Otesánek – jedno takové video vydá klidně z pár desítek fotek.
S odhalením podobných souborů může pomoct například unixový prográmek baobab, neboli Analyzátor využití disku, nicméně podobnou službu nám s trochou snahy poskytne také disketo. Začneme tím, že použijeme skriptík pro vypsání souborů fotek s jejich velikostí. Například skript:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Vypis velikosti filter_directories_by_pattern "fo" filter_directories_by_files_pattern "(PICT_[0-9]{7}\.JPG)|(Photo[0-9]+.jpg)|(fotka \([0-9]+\).jpg)" $$ load_stats print_files sub { my ($file) = @_; my $stats = $stats_ref->{$file}; my $size = $stats->size; my $kbs = $size / 1000; return "$file \t $kbs kB"; } |
Vypíše u každé fotky její velikost v (kilo)Bajtech:
|
1 2 3 4 5 6 7 8 9 |
(...) /home/martin/obrazky//fotky/Jarka/fotka (4).jpg 1541 kB /home/martin/obrazky//fotky/Jarka/fotka (8).jpg 1595 kB /home/martin/obrazky//fotky/loni/PICT_0108647.JPG 7458 kB /home/martin/obrazky//fotky/loni/PICT_0109823.JPG 7458 kB /home/martin/obrazky//fotky/loni/PICT_0111023.JPG 6956 kB /home/martin/obrazky//fotky/mobil/Photo12162.jpg 2564 kB /home/martin/obrazky//fotky/mobil/Photo45232.jpg 2658 kB (...) |
A teď trocha hrátek s unixovým shellem. Následující příkaz spustí disketo s předchozím skriptem, u výpisu prohodí sloupce (aby byla velikost první), seřadí (tedy podle velikosti) a vypíše prvních 5 souborů:
|
1 |
$ ./run-disketo-script.pl velikosti.ds 2 ~/obrazky/ 2> /dev/null | sed -r 's/([^\t]+) \t ([0-9]+ kB)/\2 \t \1/' | sort -r | head -n 5 |
|
1 2 3 4 5 |
7845 kB /home/martin/obrazky//fotky/loni/PICT_0109823.JPG 7458 kB /home/martin/obrazky//fotky/loni/PICT_0108647.JPG 6956 kB /home/martin/obrazky//fotky/loni/PICT_0111023.JPG 2658 kB /home/martin/obrazky//fotky/mobil/Photo45232.jpg 2564 kB /home/martin/obrazky//fotky/mobil/Photo12162.jpg |
Já ve složkách žádná videa nemám, ale je vidět, že fotky z loňska jsou víc, než dvakrát větší, než ostatní. Kdybych tedy potřeboval uvolnit místo, už bych věděl, na které fotky sáhnout jako první.
Kontrola zálohy
Posledním, co si ukážeme, je jednoduchá analýza záloh. To se může hodit třeba v případě, že někde najdete zapomenutou a dost možná nekompletní zálohu, a budete potřebovat zjistit, jestli náhodou neobsahuje nějaké cenné či ztracené soubory.
Vlastně je to docela jednoduché – pomocí disketa si vylistujeme všechny soubory jak na aktuálním, tak na záložním uložišti a oba seznamy souborů vypíšeme do souboru. Pak už jen soubory porovnáme, nejjednoduššeji pomocí comm (graficky pak např. pomocí meld). Pro vylistování souborů použijeme následující disketo skript:
|
1 2 3 4 5 |
# Proste vypise soubory print_files sub { my ($file) = @_; return "$file"; } |
a poté (sed je použit pro odstranění společné části cest):
|
1 2 3 4 |
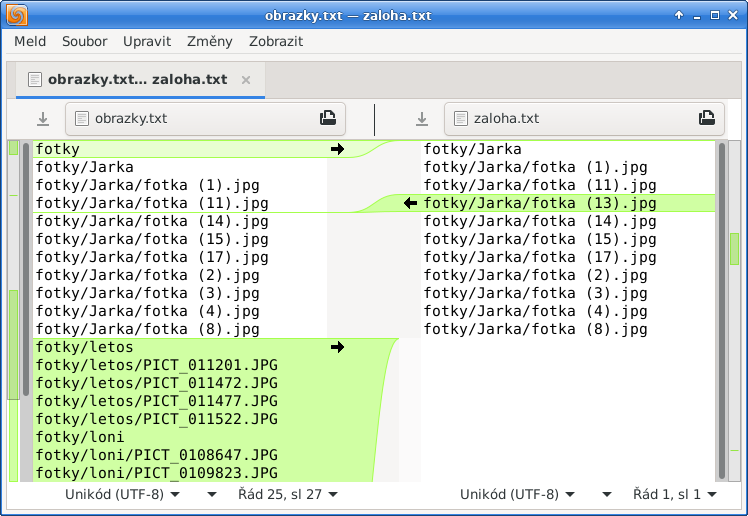
$ ./run-disketo-script.pl soubory.ds ~/obrazky/ | sed 's|/home/martin/obrazky//||' > obrazky.txt $ ./run-disketo-script.pl soubory.ds ~/zaloha/ | sed 's|/home/martin/zaloha//||' > zaloha.txt $ comm -13 obrazky.txt zaloha.txt |
vypíše soubory, které jsou ve složce se zálohou, avšak nikoliv ve složce obrazky.
Závěrem
Jak je vidět, disketo dokáže být celkem užitečná hračka. Samozřejmě opravdový potenciál tohoto pidiprográmku ocení asi jen programátor na linuxu, který si rád hraje s příkazovou řádkou, ale třeba se jednou dokopu, dopíšu dokumentaci a přidám i dummy verzi pro běžného smrtelníka.