Odešel mi počítač. Tedy – čistě technicky – on vlastně vůbec neodešel. Odešel totiž jen jeho pevný disk. Počítač (notebook, abych byl přesný) je jinak v poměrně dobrém stavu. Pomineme-li skutečnost, že některé klávesy vypadávají a jiné vydávají zvuk jak psací stroj. A také USB konektory jsou za ty roky docela vyviklané. A pochopitelně, baterka už slouží spíš jenom jako těžítko, aby notebook neklouzal po stole. A obrazovka má rozlišení menší, než podprůměrný smartphone.
Zkrátka a dobře, notebook je spíše jen zastaralý morálně, než že by byl reálně nefunkční. A že mi po téměř 10 letech přišel pomalý, bylo zapříčiněno z naprosto drtivé většiny pouze a jenom tím, že pro mě je zcela běžné mít trvale otevřený prohlížeč s desítkami záložek/stránek (tabů, rozumíme si?). A takové množství stránek s logicky nemá šanci vejít najednou do RAM, a tudíž si systém většinu z nich musí trval odkládat na pevný disk. A nasávat stovky megabytů dat z HDD (ano HDD, notebook je 10 let starý, vzpomínáte?) při každém přepnutí záložky pak prostě trvá. (A pokud člověk kromě prohlížeče otevřel i něco jiného, často se do paměti nevešel web ani jeden, a dlouhé čekání tak nastávalo pokaždé při přepnutí okna.)
Když jsem jej, z důvodů, které budu vysvětlovat v následujících odstavcích, nastartoval z flash disku (pomocí live instalačního disku distribuce xubuntu), ukázalo se, že vlastně šlape celkem slušně. Nemít paměť trvale obsazenou desítkami prohlížečových záložek, a nutnost téměř trvale přelévat stovky megabytů mezi pamětí a diskem, vlastně vyřešilo ten hlavní problém s výkonem. Dokonce jsem byl vyloženě překvapen, odhlášení a znovupřihlášení (které si vyžádala nějaká změna nastavení), celé proběhlo jen v mžiku oka (včetně zavření a znovuotevření spuštěných aplikací).
Když on vlastně při zavření prohlížeče vůbec nebyl pomalý. Chvíli mi fakt bylo líto, že bude muset odejít do křemíkového nebe.
Ale já se dnes nechci chlubit tím, jak jsou operační systémy s linuxovým jádrem skvělé, svižné a nenáročné. To konekoneckonců velmi výstižně zvládl sám jeho autor. Chtěl bych vám tady povědět příběh o zálohování, o strachu z jeho nedostatečnosti a tom, jaké fatální následky to nakonec vlastně může mít. Jak již totiž bylo zmíněno, odešel mi disk, a to je přesně ten moment, kdy se člověk modlí k bohu Gigovi, tedy patronovi všech záloh.
Zálohuješ? Ano, jistě, samozřejmě, …
Trocha teorie na úvod: zálohování má jedno jedinné pravidlo: Zálohujete nedostatečně. Nezálohujete dostatečně často, nezálohujete všechno potřebné, nemáte zálohy záloh a jejich zálohy (a nebo jejich zálohy) a další hromada neduhů, která by vydala na samosatný článek. To na úvod víme asi tak všichni.
Já, člověk, který obecně nerad kupuje jak hardware, tak i software, a tudíž vlastním pouze jeden externí disk a žádné placené cloudové uložiště, mám tedy poměrně svázané ruce se zálohováním svého počítače. Moje zálohování tak vlastně obnáší jen čas od času disk připojit a spustit skriptík, který rsync -cuje vybrané složky z počítače na něj. (Pochopitelně, některé kriticky důležité věci mám i porůznu v cloudech, ale to je spíše důsledek než záměr.) A to s tím, že tuto zálohu jsem prováděl obzvláště, když jsem věděl, že mám na disku provedené větší množství změn (např. vytřídění fotek, dokončení nějakého mého projektíku a podob.).
A pak to přišlo. Skoro
Tento systém fungoval poměrně bezproblémově (to česky řečeno znamená, že nebyla potřeba ze zálohy nic obnovovat, takže systém, který je jinak poměrně nedostatečný, neměl příležitost své slabiny ukázat světu). Změna nastala někdy před Vánoci, když se mi, poté, co pár dní pár věcí v počítači nefungovalo úplně jak mělo, objevila v konzoli při některé z činností hláška: „File system is read only“.
Bylo mi celkem jasné o co jde: Disk, nejslabší článek řetězu mého počítače, začíná selhávat. Poučen minulostí jsem systém restartoval a nastartoval z flashky výše zmíněné xubuntu. Tím pádem je možné celý disk „odmountovat“ (softwarově odpojit) a provést na něm kontrolu a opravu chyb. A samozřejmě, ještě předtím zazálohování – pro případ, že by se nezadařilo.
Takovou zvláštní vlastností linuxových systémů je, že vy si klidně můžete smazat celý disk (pro zájemce:
sudo rm -rf /) a počítač poměrně vesele poběží dál. Takže se vám klidně může stát, že vám odejde disk a vy to zjistíte až po pár dnech.
Oprava disku proběhla celkem bez problémů. A jak se ukázalo, problém se s periodou několika málo týdnů vracel zpět. To znamenalo přesně dvě věci: Zaprvé, přeinstalování softwarových balíků, které se při opravě poškodily, jsem si zautomatizoval do jednoduchého skriptíku, takže oprava disku se posléze stala celkem rutinnou („restartuj, spusť jeden příkaz, restartuj, spusť druhý příkaz, přihlaš se a funguj jak normálně“). A zadruhé: začal jsem uvažovat o koupi nového počítače.
Ale pak to spadlo úplně
Chtěl jsem si proto rychle dokončit pár rozpracovaných věcí a ze stavu „uvažuji o koupi nového počítače“ se překlopit do stavu „jsem rozhodnutý koupit si nový počítač“ a následně „kupuji si nový počítač“. A stejně jako v Jak jsem (nena)psal bakalářku: To se nakonec nikdy nestalo.
A tak jsem, konkrétně (a zcela přesně) před provedením git commit opět uviděl onu hlášku o uzamčení souborového systému. Tentokrát se oprava nespokojila s prostým proběhnutím a odstraněním nepoužívaných inod. Nyní se na disku objevilo dokonce i několik konfliktů (tj. jeden soubor byl zapsán na dvě místa či naopak – jedno místo na disku se tváří, že obsahuje vícero souborů).
A zde začíná série špatných rozhodnutí a chyb, která vyústila ve ztrátu značného množství dat.
Proč v reálném životě sakra nefunguje Ctrl+Z?
Vystrašen tím, že můj systém (a data v něm) teď aktuálně mohou vypadat asi jako slepenec Arnoldů J. Rimmerů z nepovedené snahy o vytvoření ohromného množství kopií sebe sama, rozhodl jsem se zůstat nastartovaný v systému z flashky, abych zabránil dalším škodám a provést finální zálohu. Vlastně se tím připravit na to, že disk může kdykoliv odejít. (Jinými slovy, přestat jej úplně používat, aby nebylo nic, co bych jeho nečekaným selháním ztratil.)
Nicméně, při dalším průzkumu se ukázalo, že to byla poměrně zbytečná obava; vetšina konfliktů znamenala pouze a jen to, že číslo inod některých souborů se nastavil na nulu či jedničku, a soubory, kterých se to týkalo byly vesměs buďto jen manuálové soubory a nebo soubory v koši. (To se poté později potvrdilo: po restartu zpět do „mého“ systému na disku, naběhl bez sebemenších problémů, dokonce i bez potřeby opravovat poškozené balíky.)
Fantóm Opery
Každopádně, tohoto krizového režimu jsem využil k tomu, abych provedl rozsáhlejší zálohu obsahu disku. Bohužel, jedny z nejdůležitějších dat, která jsem chtěl zazálohovat, byly právě ty ony otevřené (a v poslední době navštívené) stránky v prohlížeči, které dozajista nemalou měrou přispěly k uspíšenému konci životnosti disku. A to je věc, která prostým překopírováním souborů prostě udělat nejde. (I když, je fakt, že kdybych si do nového počítače – či jen do xubuntu – překopíroval celou složku s daty prohlížeče a prohlížeč spustil, je docela vysoká šance, že by data načetl jako svá vlastní a můj export by bylo možné provést i tímto způsobem. Škoda, že mě to nenapadlo dřív…)
Před nějakou dobou jsem si na to vytvořil poměrně roztomilý nástroj (podrobně je popsán v: Export historie prohlížeče: proč to dělat jednoduše, když to jde složitě?). Jenže pro jeho využití je potřeba mít před sebou onen prohlížeč otevřený. A to v době, kdy jsem se připravoval na to, že disk nepřežije ani start systému, natož pak spuštění prohlížeče s desítkami záložek, nějaká snaha o provedení exportu standardní cestou nepřipadala vůbec v úvahu.
„Už dlouho jsem si neexportoval historii prohlížeče. O víkendu to musím udělat.“
já, přesně dva dny před tímto incidentem
Agent s povolením klikat
Nicméně, abych si ušetřil alespoň restart systému, vymyslel jsem trik: V systému, který běží z flashky, si vytvořím nového uživatele, ale řeknu mu, že jeho domovský adresář je totožný s domovským adresářem mého uživatele v počítači. Díky tomu se tak budu moct normálně přihlásit pod tímto novým uživatelem a pracovat s mými daty v počítači, jako byly mé vlastní – a přitom bez potřeby restartu, který by disk mohl dorazit.
Pro jistotu jsem se nového uživatele rozhodl založit přes grafické nabídky. Vypadalo to, že jde o čas a na experimenty s příkazovou řádkou nebyl čas a riziko překlepů a chyb z nepozornosti veliké. A právě proto jsem přesně jednu takovou udělal.
Jedno ze základních pravidel IT říká, že pokud nějaká činnosti či operace proběhla moc rychle, je to pozdeřelé a většinou to nevěstí nic dobrého. Většinou. Asi tak v 0,1% případů to totiž bývá přesně naopak.
Když jsem totiž zvolil domovský adresář nového uživatele, vyskočil na mě dialog o pár odstavcích, který mě varoval, že tento adresář už existuje, jestli ho opravdu chci nastavit a bla bla bla… Dialog jsem jen letmo prolétl očima a zvolil „Ano“. Poté se objevilo obligátní „vyčkejte, probíhá provádění změn“. Dávalo mi to naprostý smysl! Změnil jsem uživatele, který vlastní statisíce souborů, takže se u každého z nich musí tato informace zapsat, přece. Ne?
Ne, ne. Ten dialog se mě snažil varovat, že pokud chci takto nastavit složku novému uživateli, musí být prázdná. A pokud není, bude prázdnou učiněna. (Přiznávám, kdybych se nad tím zastavil a ten dialog si 3x po sobě přečetl, nejspíš by mi došlo, jakou možnost zvolit. Vždyť ale on ten dialog vyloženě zmiňuje „pokud se bojíte ztráty dat, zvolte raději …“, bohužel měl na mysli jiná data než já.)
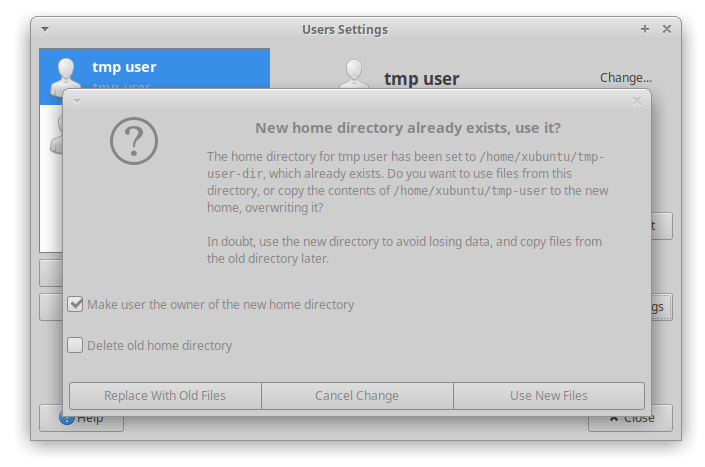
A tak se stalo, co se stalo. Domovský adresář na mém pevném disku, tedy všechny mé soubory, byly do posledního smazány. To samo o sobě je průšvih. Existují ovšem způsoby, jak jej zvrátit. Tady se asi objevila další chyba: kdybych byl býval uživatele zakládal přes příkazovou řádku, pravděpodobně by se kromě vyprázdnění jeho domovského adresáře nevytvářely žádné další soubory. Bohužel, vytvořením uživatele přes grafické prostředí automaticky vede k vytvoření základního nastavení (vytvoření složky pro Plochu, Dokumenty a podob.). Už jen to o další malý kousek snížilo šanci, že se historii prohlížeče (ale spolu s tím spoutu dalších dat, o kterých jsem neměl ani ponětí, že bych si je měl zazálohovat) už nikdy nepodaří zachránit.
Nepropadejte panice
Zde jsem ovšem zpanikařil. Vidina toho, že všechna moje data už neexistují v mém počítači, a jedinné místo, kde jsou k nalezení, je 10 let starý externí disk, mě poměrně vyděsila a tak jsem prakticky okamžitě po tomto zjištění rozhodl začít urychleně zálohu obnovovat s vidinou: „když už jsem si smazal všechno nezazálohované, velmi nerad bych přišel i o to zazálohované“.
Že jsi celou tu dobu měl někde na novém, svižném několika terrabytovém disku několikanásobně duplikovanou bitovou kopii celého rozbitého disku, pro případ, že se něco semele, a tento příběh je jen takové veselé povídání o nezávazném experimentování, že? A nebo snad ne?
Zde se asi pro kontext hodí doplnit střípek informace, že při finálním zálohování došlo k nějaké, poměrně hrubé závadě (osobně typoval bych zaškbrtnutí v napájení disku způsobeného vadným USB konektorem či kabelem), která vyústila v to, že se – nyní už i externí – disk poškodil. A při snaze jej opravit mi systém (resp. fsck) řekl něco na způsob: „Sorry jako, tak tohle nedám. Tahle chyba je tak fatální, že to musíš připojit k nějakýmu počítači s Windows a nechat to opravit je“.
Naštěstí se mi podařilo nějaký počítač s Windows oživit a disk celkem lehce opravit. Ale jistě pochopíte, že to na stresu a strachu ze ztráty dat rozhodně neubralo. Ba naopak.
A tak jsem tedy spustil kopírování mých dat ze zálohy na externím disku zpět do počítače. Asi po půl hodině a necelé stovce GB přenesených dat mi došlo, že já bych se vlastně mohl pokusit obnovit některé ze smazaných souborů, před tím, než si je přepíši obnovením zálohy.
A tak jsem uvažoval, co bych si asi tak mohl ještě zkusit zachránit. Ale považoval jsem to za předem prohrané, protože – obnovit jde jen soubory, nikoliv složky či celou adresářovou strukturu – a já, když už bych něco potřeboval zachránit, tak by o rozhodně nebyl jeden jedinný soubor, ale celá složka. I v tom jsem nakonec chyboval.
Po asi půl hodině kopírování jsem si ještě jednou vzpomněl na můj článek o exportu historie prohlížeče. Jedna kapitola se věnuje trošku postrannímu tématu – tomu, jak vlastně celý ten složitý postup exportu je možné s určitou nepřesností obejít jedním SQL dotazem nad jedním SQLite souborem.
Vyhlašujeme pátrání po souboru neznámého jména, střední velikost, přípona žádná
A tak jsem se pustil do hledání právě tohoto souboru. Teoreticky to triviálně: spusť program foremost a s jeho pomocí vyhledej všechny obnovitelné soubory a nech je obnovit. Z nich vyber jen soubory typu „SQLite databáze“. Z nich vyber ty, které obsahují databázi požadovaného schématu (věděl jsem, že musí obsahovat tabulku „favicons“). Pomocí mého nástroje vyexportuj (alespoň část) historii z tohoto souboru. A je hotovo!
První zádrhel nastal hned v prvním kroku. Program foremost nezná soubory typu „SQLite databáze“. Ty bylo potřeba ručně dodeklarovat (naštěstí nic složitého, stačilo jen specifikovat čím soubor začíná, tj. magic number, což je veřejně známá věc).
Druhým problémem bylo, že foremost obnovuje buďto všechny soubory všech známých typů, nebo jen určité zvolené typy (JPG, docx, ZIP, …). Bohužel, možnost obnovení zvolených typů se nevztahuje na ručně deklarované typy, takže jsem musel bohužel obnovit úplně všechny soubory. S ohledem na to, že na externím disku, který byl pochopitelně jediným možným cílovým zařízením, už tak ležela záloha více než poloviny mého počítače, a k tomu ještě nějaké smetí k tomu (které fakt nebyl čas uklízet), docela jsem se toho obával. Z logiky věci – zachraňovat data z 400GB disku na disk, kde je volných necelých 100GB, matematicky nevychází i kdyby se podařilo souborů zachránit jenom čtvrtinu.
K mému překvapení to ovšem po pár hodinách nezhavarovalo na tom, že by se disk zaplnil zombie fotkami a tunami dávno smazaných PDFek z dob studí, nýbrž na skutečnosti, že se naplnil maximální počet souborů ve složce. Nevadí, tak u toho zkrátka budu muset sedět, sledovat to, a čas od času pomazat všechny obnovené fotky a videa, dokumenty, ZIPy, a zkrátka všechno, co nejsou databáze SQLite.
Externí disk může mít v každé složce maximálně šedesát pět tisíc pět set třicet šest souborů. Neptejte se mě jak to vím, prostě to vím.
Druhý problém, jak se ukázalo, se jala být skutečnost, že na disku je celá řada souborů, které začínají stejně jako databáze SQLite, nýbrž SQLite databází nejsou. V jednu chvíli to dokonce vypadalo, že nějaká aplikace (osobně se domnívám, že právě prohlížeč) má na každý databázový soubor jeden soubor textový, obsahující informaci o tom, v jakém formátu ta databáze je (to celkem dává smysl, než aby aplikace zkoumala co to je za typ databáze, podívá se do odpovídajícího pomocného souboru a ví to ihned).
Takže když jsem se zaradoval, že se mi podařilo zachránit již pár stovek SQLite databází během prvních pár minut, ukázalo se, že jen možná 1% jsou skutečné databázové soubory. Doplnil jsem si tedy jednoduchý filtřík, který odmazával soubory, které nejsou SQLite databáze, i když se tak pro foremost tvářily.
Z nižsích desítek opravdových SQLite databází jsem poté už jen průběžně filtroval ty, které (ne)obsahují kýženou tabulku/tabulky a dostal jsem se k jednotkám souborů. Současně jsem ale dále procházel disk a hledal další, pro případ, že by nějaký takový soubor byl umístěný někde vzadu.
Říká se, že když poskytnete skupince opic ideální podmínky k životu a do výběhu jim dáte neomezený zdroj papírů a tužek, za pár miliard let čistou náhodou sepíší celé dílo Shakespeara. Tak nějak jsem se cítil, když se mi při čtení dat z disku najednou změnil titulek okna na nějaké smetí. V těch miliardách bytů dat se totiž vyskytla escape sekvence na změnu titulku okna. Ano, někde na mém disku se nachází série znaků „\033]0;“ a „\007“.
Toto celé trvalo několik málo dní, při kterém procedura v různých stádiích spadla právě z důvodu přeplění výstupního adresáře. Takže jsem se nakonec s prohledáváním ani nedostal na úplný konec disku. Nicméně, dle prvotního průzkumu to vypadalo, že soubor, který hledám, už jsem dávno našel. Jak by si člověk domyslel – prohlížeč je jedna z prvních věcí, kterou člověk v počítači spouští, takže dává smysl, že jeho soubory budou „někde na začátku disku“, než se stihne zaplnit ostatními daty.
Na pitevně
Pátrání po zemřelém souboru jsem tedy ukončil a jal se prověřit kandidáty. Bohužel, žádný z nalezených souborů nebyl bez poškození. U jednoho namátkou vybraného jsem si vylistoval jeho obsah, a po pár megabytech dat jsem narazil na poměrně jasný a srozumitelný text nějakého konfiguračního souboru pro grafické prostředí (ale těžko říct, dost možná někde mezi těmi nečitelnými daty byl i nějaký PDF dokument z mé snahy o obnovení zálohy).

Poměrně nešťasten a vědoma toho, že je zle, jsem z povinnosti vyzkoušel pár „osvědčených“ triků, jak zachránit rozbitou SQLite databázi. Pochopitelně, žádný z nich není stavěný na to, že vám někdo přepíše kus souboru něčím úplně jiným, takže naprosto bez úspěchu.
Zkusil jsem také sáhnout po řešení ze světa Microsoft Windows. Našel jsem totiž nějaký „zaručeně 100% funkční SQLite prográmek na opravu poškozené databáze“. No, skutečnosti, že odkaz na stažení vedl na stažení úplně jiného prográmku (a ten „reálný“ odkaz byl kdesi dole v rožku malým písmem) a že po stažení a spuštění toho pravého, aplikace vypadala úplně jinak, než v návodu, přeskočím, protože na to už jsem ve světě Microsoftích technologií tak nějak zvyklý.
A jak to dopadlo? Jednoduše: Ten skvělý, profesionální a 100% funkční prográmek nedokázal z databáze vytáhnout ani seznam tabulek v ní obsažený. Tedy něco, co bez problému zvládl i výchozí klient SQLite. Na neúspěch jsem byl připravený, ale tato pointa mě vyloženě pobavila.
Na pohřbu je každý generál
A tak tu teď sedím, koukám na 8 zachráněných SQLite databází, z nichž některé patrně obsahují nějaké informace o mnou naposledy navštívených stránkách, ale notně poškozené, takže bez přímé cesty, jak z nich tyto informace dostat. Ustoupil jsem z toho, že bych rád měl kompletní zálohu celé historie prohlížeče. Stalo se pro mě přijatelné získat jen seznam naposledy navštívených stránek a data jejich posledních návštěv. Nakonec to vypadá, že – budu-li mít štěstí – podaří se mi získat alespoň pár webových adres několika navštívených webů v poslední době.
Rád bych se podíval na standart SQLite a na formát jeho databázového souboru. V ideálním případě se mi podaří přesně identifikovat přepsanou část a, řekněme, vyprázdnit ji. Sice přijdu o některá data (v ideálním případě by se však netýkala samotného sezanamu webů, ale např. cookies), ale mohlo by se mi podařit databázi zprovoznit a umožnit tak její export.
Ale domnívám se, že nejspíš stejně zkončím u toho, že celý soubor prostě prohledám na výskyty všeho, co začíná znaky „http“ a to si prostě někam uložím. Operační systém unix (a to zdědil i jeho pravnuk Linux) vznikl za účelem vyhledávání textů, takže by to myslím byla celkem vkusná tečka za celým tímto příběhem.
Závěrem
Co říci závěrem? Zálohujte! A ještě bych dodal: Zálohujte! A na závěr: Zálohujte!
Tento příběh naštěstí nedopadl tak špatně. Vlastně by se dalo říci, že dopadl dobře (ale to nemohu, protože ještě zálohu nemám v novém počítači). Co jsem se tímto snažil vypíchnout je skutečnost, že i když má člověk to nejdůležitější (myšleno třeba 99%) zazálohováno, a octne se v ohrožení, že záloha ani toho jednoho procenta už nebude možná, nesmí za žádnou cenu panikařit.
Jak se ukázalo, počítač (či disk) nebyl v tak špatném stavu, aby nemohl ještě pár dní fungovat vesměs normálně dále. Měl jsem tedy (s velkou pravděpodobností) dostatek prostoru na to, si v klidu dozálohovat zbylé 1% dat. Ale šok z toho, že „počítač kleknul“ a obavy z rizika, že selže i záloha zbylých 99%, zabránily jinak běžnému odstupu, nadhledu a racionálnímu vyhodnocení situace. Je to přirozené – člověk se dostane pod palbu emocí a v takové situaci si prostě nedokáže říct: „Hm, je to blbý, ale teďka už to raděj vypnu a do zítřka promyslím, co s tím. Teďka bych určitě jen napáchal víc škody než užitku.“
A přesně na toto se snažím upozornit. Osobně doufám, že se nikdo do podobné situace nikdy nedostane, ale když už ano tak: zachovejte klid. A pokud jde opravdu o život, svěřte počítač do rukou odborníků, čím dřív, tím líp. Těch pár stovek za to přece stojí, ne? Vždyť jde přece o život.
A víte, co je na tom všem nejlepší? Že si toto někdo někdy bude číst zcela určitě poté, co do vyhledávače vložil frázi typu: „pomoc klekl mi počítač jak z něj zachránit data“ a jediné, co mu v této situaci tento článek dá bude to, že mu řekne: „jo, je to tak, jsi trouba, měl sis všechno pořádně zálohovat“.
RIP Lenovo „Lenny“ Thinkpad E520, 2012 – 2022