Stala se mi – slovy klasika – takový ošklivý a skoro bych řekl zlý, nepěkná věc. Zavřel jsem si okno prohlížeče se spoustou záložek (karet, panelů) a omylem si toto zavřené okno nahradil nově otevřeným prázdným. Po jeho zavření se tak „naposledy zavřeným“ oknem stalo toto nové, prázdné a to původní bylo nenávratně ztraceno. Leda, že bych vynalezl stroj času a vrátil se do chvíle, kdy jsem tyto mé stránky měl naposledy otevřené...
A tak jsem začal bádat, jak z prohlížeče Opera vydolovat historii v nějakém rozumném, tedy strojově čitelném formátu. První myšlenka byla prohledat domovský adresář a hledat vše, co by mohlo mít co dočinění s Operou (tedy ~/.config/opera a ~/.cache/opera ), jestli tam třeba nenajdu soubor history.xml. Bohužel nic takového a googlení mě akorát přivedlo k myšlence, že něco takového dost dobře není možné. (Fail #1: V závěru se ukázalo, že to tak úplně není pravda, ale k tomu se dostaneme.)
Prohlížeč Opera je vlastně Chromium. Teoreticky by tak mnohé z toho, zde uvedeného, mohlo fungovat i v Chromiu a tudíž i v Google Chrome a snad dokonce možná i v Microsoft Edge.
Pár sekund jsem také uvažoval o tom, že by to mohl umět nějaký plugin. Prohlížečové pluginy obecně ale nemám zrovna v lásce, kromě blokování reklamy (což ovšem Opera dělá nativně), mám pocit, že jen prohlížeč zbytečně zpomalují. Navíc je to další potencionálně škodlivý (resp. děravý či napadnutelný) kód, ještě navíc přímo v prohlížeči.
Trocha Javascriptu ještě nikdy nikoho nezabila …
Já
Navíc, možná proto jsem inspirován youtubery jako colinfurze nebo Michael Reeves (#karanténa) začal uvažovat o nějakém šíleném a bláznivém řešení. Navíc, jsem (si) chtěl ukázat, že se Tom Scott mýlí a hackovat jde stejně dobře i na Linuxu. A v momentě, kdy jsem zjistil, že historie v Opeře je jen další „HTML stránka“, bylo rozhodnuto: Trocha Javascriptu ještě nikdy nikoho nezabila! (Upřímně se obávám, že asi ano, tím si ale nekažme tuhle chytlavou frázi.)
Verze 1.0: vize
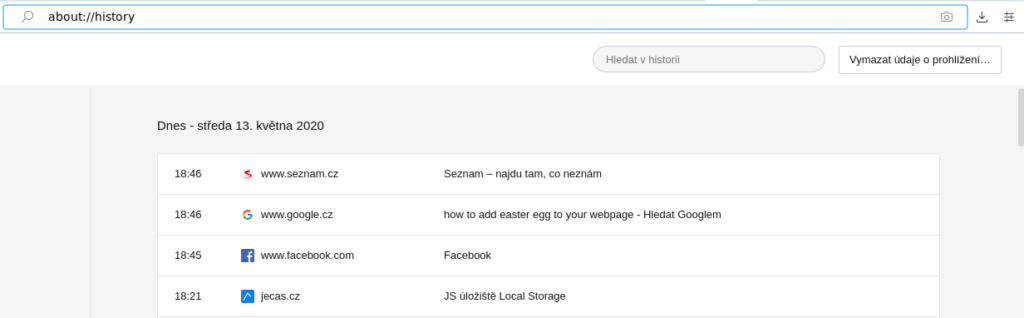
Moje myšlenka byla tedy jednoduchá – budu-li si chtít zazálohovat historii prohlížeče, otevřu „stránku“ historie (dostoupnou mj. pod url about://history), otevřu vývojářskou konzoli (tu vám na této stránce Opera oficiálně neumožní rozbalit, ale Ctrl+Shift+I funguje), vložím tam nějaký kus kódu, odentruju – a pár vteřin či desítek vteřin počkám. (Fail #2: Je zajímavé, že mě celou dobu nenapadlo prostě pomocí Ctrl+S celou stránku uložit a pak si ji někde v klidu zpracovat.)
Samotný kód pak měl za úkol projít celou stránku, sesbírat záznamy historie a „uložit je“. Nastala tedy otázka, jak/kam data „uložit“. Prohlížečový Javascript nemá moc možností jak ukládat data – ten nejzákladnější, tj. localStorage, se v Opeře sype do nějakých „data“ souborů kdesi v konfiguraci. Navíc bych si troufl říct, že by na této stránce ani nefungoval.
A tak jsem si řekl, že když už bude nějaký Javascriptový kód běžet v prohlížeči, proč rovnou nevytvořit jednoduchou node.js webovou službu, které bude prohlížečový skript data posílat? Taková služba pak může data sypat třeba do sqlite databáze. #Too_much_javascript_to_handle
Tak třeba by nikoho nezabilo ani trochu víc Javascriptu …
Já o pár vteřin později
Teoreticky. Pustil jsem se tedy do toho. Hned první drobný zádrhel byl, že Opera záznamy v historii zobrazuje (resp. načítá a zobrazuje nové a nové) postupně jak člověk scrolluje dolů stránkou (ne moc překvapivě). Nestačilo tak pouze otevřít stránku a vyextrahovat záznamy – bylo nutné odscrollovat postupně až dolů a nechat postupně načíst všechny záznamy.
Verze 1.1: první krůčky
Řekl jsem si, že než listovat celou stránkou úplně dolů a pak odesílat na node.js službu tisíce záznamů, mohl bych sledovat změny ve stránce a „reportovat“ průběžně všechny přidané záznamy. Pochopitelně s automatickým scrollováním, jakmile by byly všechny nově přidané záznamy bezpečně zpracovány.
Dalo se totiž očekávat, že Opera nebude úplně nadšená z toho, že někdo listuje historií až na úplné dno. Dle mých odhadů se mohlo jednat klidně o 10 tisíc záznamů (Fail #3: aktuální odhad mám cca 100 stránek za den, za rok a kousek tedy téměř 50 tisíc) a s ohledem na to, jak titěrně vypadal posuvník (scrollbar) už po prvních pár scrollech dolů, kdy jsem projel historii za poslední dva dny, dalo se tušit, že to bude záhul. (Fail #4: Při hlubším zkoumání vyprodukované databáze, jsem zjistil, že scrollování se vždy zastavilo asi na 95. dnu a další historie už se nenačítala. Podařilo se mi dohledat, že Opera si totiž pamatuje historii jen asi tři měsíce zpětně. Ve výsledku tak stránka byla asi 10x menší, než jsem očekával.)
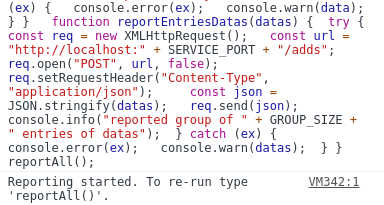
Vytvořil jsem tedy skriptík, který monitoroval změny v dokumentu a reportoval nově přidané záznamy. S ohledem na to, že záznamy se přidávají po určitém počtu (konkrétně po stovce) a nikoliv po celých dnech, bylo potřeba sledovat i to (záznamy jednotlivých dnů Opera zobrazuje na oddělených panelech, takže přibývají jak dny v panelu posledního dne, tak i nové panely se svými záznamy).
Přidal jsem i automatické scrollování po skončení zpracování (a pro jistotou i nějaké čekání, přecijen natažení a zobrazení stovky záznamů vteřinku, dvě, pět zabere). Vše fungovalo naprosto skvěle, jen s jedním drobným zádrhelem – po asi třech odscrollováních došlo k zřejmě internal erroru v Opeře (prostě spadl kód, který měl renderovat HTML na základě dat z backendu) a stránka přestala na scrollování reagovat. Vlastně se tak trochu celá rozbila a přestala reagovat tak nějak všeobecně.
Verze 1.2: jeden krok vpřed, dva vzad
To mi docela zhatilo plány a vzhledem k tomu, že nepomohlo ani navýšení čekání (pro případ, že by šlo o souběh) či trochu efektivnější/efektnější způsob zpracování přidaných záznamů, musel jsem se s tímto poměrně elegantním řešením rozloučit.
Došlo to tak daleko, že jsem se chvíli dokonce hrabal zdrojovými kódy Opery, snažil jej zprvu debuggovat a po neúspěchu studovat, jak vyvolat načítání nových záznamů ručně, tj. bez scrollování. To se mi nepodařilo, zato jsem našel přímo modul implementující dotazování nad historií. Tedy něco, co by mi vracelo záznamy přímo jako Javascriptové objekty, bez nutnosti parsování HTML, resp. proházení stromu dokumentu!
Funguje to perfektně, až na to, že vlastně vůbec…
Bohužel, ani to se mi, zcela nepřekvapivě, nepodařilo rozchodit (povětšinou jsem byl poslán do oněch partií různými vrstvami bezpečnostní politiky) (dává to smysl, kdyby si jen tak nějaký Javascript mohl takhle hrát s interními věcmi prohlížeče, asi by prohlížeč brzo doprohlížečoval) . Koneckonců, v jednu chvíli jsem si říkal, že dost možná i proto mi můj skriptík padal – Opera zkrátka možná blokovala automatizované zpracování stránky. (Když nad tím tak přemýšlím, tak to je asi hloupost, padalo to na něčem ohledně stylů, což moc nevypadá jako úmysl.)
Dospělo to až tak daleko, že jsem chvíli koukal na stránku dokumentace k Browser History API pro vývojáře pluginů. Ani pořádně nevím, jak jsem se tam vlastně dostal, ale s ohledem na to, že jsem si plugin nechtěl instalovat jako uživatel, natož si jej přímo vyvíjet, stránku i celou myšlenku jsem rychle opustil a lehce ustoupil z mých požadavků.
Verze 1.3: Tak už to zmáčkni!
Rezignovaně jsem opustil představu, že celý problém vyřeší jedna nodej.js služba a jeden kód prostě vložený do konzole prohlížeče, a vytáhl bazuku. Sáhl jsem totiž po prográmku xdotool, který emuluje, resp. „fejkuje“ primitivní akce uživatele, tj. pohyb nebo klikání myší a stisky kláves.
Scrollování jsem tedy vyřešil jednoduchým Bashovým skriptíkem, který do svého ukončení prostě pořád dokolečka mačká Page Down (pochopitelně, opět, s nějakým čekáním). Spolu s tím jsem také z mého prohlížečového kódu vyhodil celý ten problematický monitoring stránky a prostě jej nechal staticky a jednorázově projít celou stránku a naposílat všechny nalezené záznamy.
Tohle celé jsem zabalil do jednoduchého skriptu, který:
- Požádá uživatele, aby otevřel v prohlížeči historii (to by samozřejmě šlo udělat jedním příkazem, ale myslím, že to celému skriptu přidává na „dramatičnosti“)
- Řekne mu, aby si otevřel vývojářské nástroje (opět, i to by šlo udělat pomocí
xdotools, ale chtěl jsem ponechat co nejvíc kontroly uživateli) - Spustí skript na scrollování dolů
- Jakmile stránka dojede dolů (nebo kdykoliv si uživatel usmyslí), má jej ukončit
- Nahodí se node.js služba, založí se databázový soubor, vytvoří tabulka
- Uživateli je předložen částečně minimizovaný (tj. bez nadbytečných bílých znaků) Javascriptový kód, který má spustit v prohlížeči
- Po doběhnutí uživatel dá pokyn k odpojení od databáze a zrušení služby
- Na závěr je jen pro kontrolu vypsán počet záznamů v databází a skript končí.
Nezbývalo, než to celé spustit. Všechno klapalo, dokonce i reportování node.js službě. Akorát to spadlo po pár sekundách, protože prohlížeč nedokázal udržet tolik otevřených spojení současně – XHR požadavky se totiž v základu posílají asynchronně, tedy se nečeká na dokončení předešlého a tudíž je prohlížeč chtěl poslat prakticky všechny v jeden okamžik. Opraveno a nyní už celý skript proběhl a nasbíral skutečná data. Jenže …
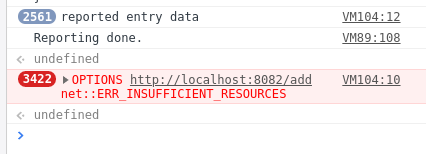
Verze 1.4: Zrychlujeme
… jenže stále tam bylo několik „ale“. Tak zaprvé, kód, který měl uživatel zkopírovat do prohlížeče, jen slepě odstraňoval nadbytečné bílé znaky. Což, jak jsem záhy zjistil, mělo nedozírné důsledky v případě, že v kódu byl někde jednořádkový komentář. V takovém případě tedy zakomentoval zbytek celého kódu. Oukej, nějakým způsobem jsem tam doplnil odstraňování jednořádkových (a když už, tak už i víceřádkových (bo minimizace!)) komentářů.
Další problém, který mě trápil, byla rychlost nahrávání. Nebylo nijak zvlášť překvapivé, že vzít jeden JSON záznam, poslat ho přes XHR na node.js server a tam ho jedním dotazem vložit do databáze bude při tisících takovýchto záznamů docela neefektivní. Přidal jsem tedy dávkové zpracování.
K mému poměrně velkému překvapení se nahrání tisíce záznamů propadlo z dvou a půl minut na 14 sekund (při posílání po 10), resp. na 6 sekund (při posílání po 20) nebo necelé tři sekundy (při posílání po 50). Musel jsem kvůli tomu ale navýšit maximální velikost požadavku na 10MB (občas bylo zřejmě některé URL příliš dlouhé) (Fail #5: zřejmě to nebylo URL, ale favicona ve formátu data:uri). Nakonec jsem tedy nechal velikost dávky na 20 (při 50 by se zvyšovala šance že node.js odmítne celý balík 50 záznamů, o které bych tak přišel).
Pak už jen drobnosti jako odpojit se korektně od databáze při ukončování, a doplnit trošku informativních výpisů (jak do konzole v prohlížeči, tak při běhu hlavního skriptu).
Mimochodem, shruba v této době (když jsem při jednom testování nechápavě zíral, proč se scrollování zastavilo na datu někdy v únoru – a dál ani krok) zjistil, že Opera si pamatuje historii jen tři měsíce zpětně. Na jednu stranu docela šok a zklamání, na druhou stranu motivace mít skript připravený k opětovnému použítí. Ale o tom pozděj, teď jedna odbočka.
Odbočka 1.1: Primitivní ale funkční
Dobře, ale – říkáte si, co se sesbíraným seznamem navštívených stránek? Samozřejmě, až budu mít sesbíraných víc záznamů, než poslední tři měsíce, půjdou dělat docela zajímavé statistiky. Od nenajvštěvovanějších serverů přes opakovaně navštěvované přímo konkrétní stránky, až po histogram návštěv různých webů dle denní doby/dne v týdnu. #Science
A nebo si vytvořit obrázek se faviconkami všech navštívených stránek. Tedy tak trochu něco jako reddit place nebo The Million dollar homepage – jen sestavené mnou samotným.

Koneckonců, z tohoto důvodu již úplně první verze exportéru historie pracovala s cestou k faviconám stránek zobrazených v historii. Myšlenka tedy byla jednoduchá – skript vezme vyexporotovanou databázi navštívených stránek a vygeneruje jednoduchou HTML stránku s obrázkem (faviconkou serveru) pro každý záznam z historie.
Teprve v tento moment jsem se hlouběji podíval na favicony získané z historie. Zjistil jsem, že to vlastně vůbec nejsou adresy reálných ikonek, nýbrž jen odkazy do interní cache favicon Opery. Tedy nepoužitelné. Použil jsem tedy starý trik, nechal jsem si vylistovat jen názvy serverů a ve stránce vyjmenoval všechny obrázky s URL https://SERVER/favicon.ico. Samozřejmě ne všechny takové existují (typicky třeba mnou docela často navštěvované mapy.cz) a tak se u nich pomocí alternativního textu zobrazil křížek. (Asi by šlo na jednotlivé servery poslat požadavky, ty zparsovat a získat přímo konkrétní adresy faviconek, předmětem tohoto skriptíku ale bylo jen rychlé a plus mínus funkční řešení.)
Na odzkoušení hypotézy celkem cool, ukázalo se, že to může fungovat. Ale jak pravil klasik – not great not terrible.
Odbočka 1.2: Hloupé, ale ještě funkčnější
Napadlo mě ale, že favicony by si prohlížeč zcela určitě měl cachovat. A taky, že (bavíme-li se stále o Opeře) – ano! V sqlite databázovém souboru ~/.config/opera/Favicons se nachází parta tabulek obsahující informace o faviconách. Pak už stačilo jen nastudovat si jejich strukturu a napsat stručný dotaz, který vylistuje URL favicon pro všechny servery. K mému překvapení, prohlížeč si pamatoval všechny favicony pro všechny servery v nedávné historii. (#Fail 6: Historii? Ano, cache favicon je vlastně také historie. Pamatuje si seznam navšítených adres (pro každou z nich i faviconku) a datum a čas posledního přístupu. Nevýhodou ale je, že si u každé stránky pamatuje vždy jen poslední přístup. Teoreticky by to ale jako jednoduchá strojově čitelná historie mohlo postačovat.)
Tentokrát už by mi obyčejný Bashový skript nestačil, takže jsem sáhl po Pythonu. Prostě si pro každý záznam v historii pomocí jeho serveru najde odpovídající URL favicony a tu vypíše jako obrázek. Protože ale mám k dispozici informací víc, každá faviconka je klikatelná (vede přímo na patřičnou stránku) a s popiskem (tooltipem) (titulek stránky). (Fail #7: Vzhledem k tomu, že historie a cache favicon se nacházejí v různých databázích, mám jejich „spojení“ řešené až na straně v Pythonu. Sqllite samozřejmě umí i to, pak by se skript zkrátil a většinu práce by odvedl jeden SQL dotaz. Skript by pak šel napsat i přímo v Bashi bez nutnosti Pythonu.)

Tento skriptík je tedy trochu víc promakanější, ale hlavně – zobrazí favicony všechny (pochopitelně, pokud v mezičase některá nebyla přesunuta), a to včetně tooltipů a vlastně i konkrétních URL (po přejetí nad odkazem se jeho adresa zobrazuje někde dole). Jedinou nevýhodou je, že při generování musí být zavřená Opera. Databáze je pochopitelně Operou hojně využívána a je tak tímto procesem blokovaná. To trošku kazí dojem z vygenerované webové stránky, ale myslím, že přínosy jasně vedou.
Verze 1.5: budoucnost
Dobře, ale zpět k exportéru historie. Jak jsem zmiňoval, nyní už je dokončen a plně funkční, aktuálně se již jen dolaďují některé detaily, které usnadní dlouhodobější používání.
Jeden z nich by určitě mělo být nevkládání duplicitních záznamů (když budu zálohovat každý měsíc, předposlední a předpředposlední měsíc budu vždycky dvakrát). S tím souvisí, že skript by neměl vyžadovat neexistenci databázového souboru při spuštění a – nejlépe cestu k němu nemít zadrátovanou napevno, ale na vyžádání od uživatele.
Také s ohledem na zkušenosti získané tvorbou generátoru stránky s faviconkami, odebrat z exportu favicony. Je to hodnota nicneříkající a tudíž zbytečná. Obdobně, datum a čas návštěvy stránky by asi taky bylo rozumné ukládat jako datum a čas a ne jako text natvrdo vystřižený ze stránky.
Zapracovat by se dalo i na generátoru stránky s faviconkami. Například ikonky rozházet, a zobrazovat jejich velikost podle návštěvnosti daného serveru (tj. něco jako tag cloud). Nebo je prostě a jednoduše jen náhodně zamíchat.
Závěr
Závěrem bych tradičně jen uvedl odkaz na GitHub projektu (pokud odkaz nefunguje, pak ještě nebyla dokončena verze 1.5). Nepředpokládám, že by se našel někdo, kdo si jej stáhne či na něm nedejbože bude dělat úpravy.
Vlastně celý tento článek vznikl jen jako výpis strastí, se kterými se člověk může při takovém tom domácím hackování setkat. Dá se očekávát, že s prvním redesignem Opery se minimálně ta prohlížečová část celá rozsype, ale třeba do té doby nasbírám alespoň nějaké informace o mé aktivitě na internetu. A nebo třeba ne. Možná mě přestane bavit pokaždé nechat dlouhé minuty (kolik je to celkem se mi ještě nepodařilo přesně určit, celkový export jsem spouštěl vždycky přes noc) čekat, než se odscrolluje stránka s historií.
A nebo se mi podaří dopátrat alespoň některé ze ztracených záložek (stránek, panelů, karet), kvůli kterým tohle celé vzniklo. Ale musím se přiznat, že na to jsem v průběhu vývoje tohoto udělátka úplně zapomněl.